什么是数字化劳动力?中国人口老龄化是当今备受关注的社会问题之一。随着人口结构的变化,适龄劳动力人口比例逐年下降,这一问题变得更加严峻。
根据统计,中国15-64岁的适龄劳动力人口比例在2010-2020年逐年下降,从2010年的74.53%降至2020年的68.55%。根据《世界人口展望》2019年版的预测,未来这一比例将持续下降,到2050年可能降至59.78%。适龄劳动力人口比例的下降导致老龄化程度不断加深,国家面临着人口结构失衡和养老负担加重等问题,这给经济和社会发展带来了极大的挑战。
在这一背景下,数字化劳动力应运而生。麦肯锡在《数字化劳动力白皮书》描述,数字化劳动力主要依托新型技术来完成企业对前端用户及内部员工的服务优化,以及中后台运营协同作业等任务。传统劳动力与数字化劳动力相结合,可为企业建立“智能员工队伍”,通过科技赋能传统劳动力提高生产效率,降低运营成本,并优化员工体验。数字化劳动力为企业优化劳动力资源配置这一课题提供了新思路。数字化劳动力在去年和今年的两会上也得到了广泛热议。
全国政协委员林绍彬做出提案《关于以福建省为试点,大力推进“数字化劳动力”广泛应用的建议》,建议以政府为主导,建立城市级数字化劳动力运营中心,加快数字化劳动力在不同领域的场景化应用。
全国政协委员姚卫海做出提案《关于推动数字化劳动力广泛应用于基层智慧治理的建议》,建议以全国范围内人口多、密度大的区县级基层社区为一期试点,逐步让数字化劳动力融入基层智慧治理模式。
全国人大代表霍涛做出议案《关于推动数字化劳动力在智慧法院建设中广泛应用的建议》,建议智慧法院建设中除了软件系统平台的开发与增加,增加数字化劳动力建设 ,优先在区县级法院进行先行试点,尽快解决基层群众心中“急难愁盼”的问题。
可以预见的是,数字化劳动力将会被越来越多的企业和组织所使用,成为数字化转型的重要抓手,帮助企业和组织降本增效,提高竞争力。
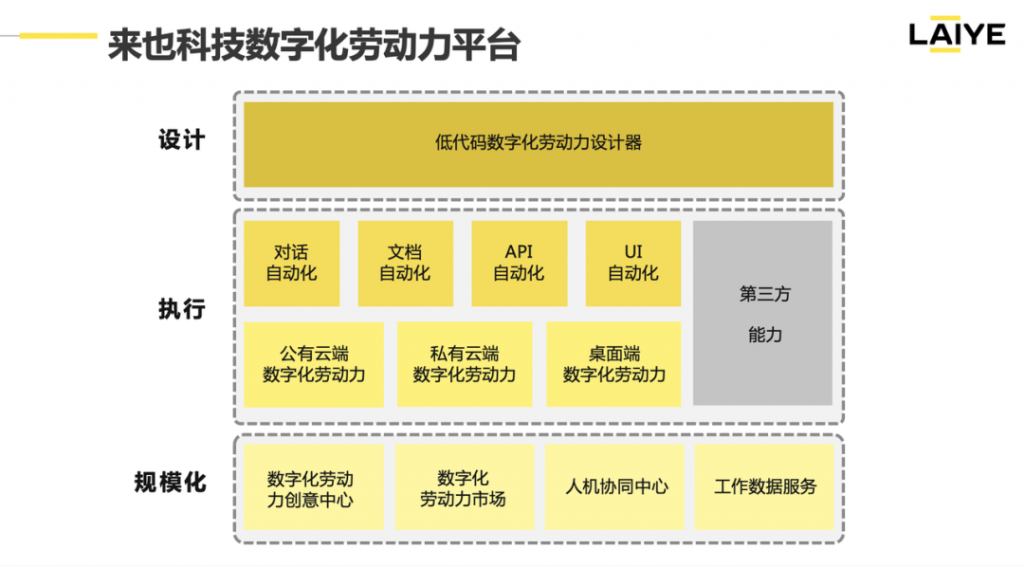
来也科技数字化劳动力平台来也科技在2022年发布了全新的数字化劳动力平台(如下图所示)。我们将数字化劳动力分为设计、执行和规模化三个阶段。
01
在设计阶段,平台提供一个统一的低代码数字化劳动力设计器,开发者可以利用它将数字员工所需的各种技能编排起来,设计出符合业务场景需求的数字员工。
02
在执行阶段,平台将不同的自动化能力以原子化的方式进行拆分。其中,对话自动化使数字员工具备人机对话交互的能力,文档自动化使数字员工具备对各类半结构化和非结构化文档进行理解和处理的能力,API自动化使数字员工具备通过接口连接不同系统的能力,UI自动化使数字员工通过模拟键盘鼠标操作来实现对各种软件的操作。这些自动化能力进行编排后,可以在公有云、私有云、桌面端进行执行。
03
在规模化阶段,平台提供一系列的应用让组织能够更好地管理数字员工,让人类员工和数字员工更好地协同,从而实现数字员工的规模化。这对于企业和组织来说,可以大大提高工作效率,优化资源配置,并提高生产力,提高组织的竞争力。
大语言模型的颠覆性
大语言模型技术的突破,将给数字化劳动力也带来巨大的影响。我们认为,大语言模型的两个显著特点,将重塑数字化劳动力。首先,大语言模型提供了通用的自然语言处理(NLP)能力。传统的NLP领域需要为不同的任务设计不同的方法并训练不同的模型,这导致训练和使用模型解决具体NLP问题的门槛和周期较长。与此不同的是,大语言模型将不同NLP任务都当成文本生成任务来处理,并验证了预训练的大语言模型能够很好地完成多种NLP任务。因此,大语言模型将彻底改变我们解决NLP问题的方法,未来数字化劳动力所需的大部分NLP能力都可以使用大语言模型来满足。
其次,大语言模型提供了一种自然的人机交互形式,即对话式用户界面(Conversational User Interface, CUI)。大语言模型的输入和输出都是自然语言,使得人和机器通过自然语言交互成为可能,这将大幅降低人们使用软件的门槛。同时,ChatGPT展示了人通过对话来“调教”机器的可能性,这是一种全新的人机协同方式。大语言模型驱动的人机交互和人机协同的范式转变,使得数字化劳动力变得更易用、更普及。这将极大地促进数字化劳动力的发展和应用,并为企业和组织提供更高效、更人性化的工作方式。
大语言模型如何重塑数字化劳动力
数字员工的能力越来越强
在大语言模型的加持下,数字员工的能力将变得越来越强,主要体现在以下两方面。
首先,在过去的数字员工需要通过开发或训练才能具备相关能力。有了大语言模型的加持,数字员工能够在不需要训练的情况下完成很多基本的工作,比如翻译、写文章、写代码等。这些能力虽然和具体的业务没有直接关系,但这都是非常基础的能力,因此能够为业务带来很大的价值。
其次,大语言模型提供了通用的语言理解和生成能力。在一个企业或组织里,非结构化数据占据了很大的比例,而这些数据往往需要通过人工处理才能变成有用的信息。借助大语言模型,数字员工就能够对非结构化数据进行理解和处理。举个例子,未来企业可能会使用一类数字员工,它们能够将企业内产生的所有非结构化数据(如会议、聊天、邮件、文档等)全部进行结构化,以供分析和决策。这将为企业带来更精准的数据分析和更高效的决策过程。
数字员工的开发将越来越简单
为了让数字员工大规模落地,我们需要降低数字员工的开发门槛。虽然来也科技在全球范围内拥有超过75万开发者,但这个群体在所有知识工作者中占比较小,说明数字员工的开发门槛仍然很高。随着大语言模型技术的发展,我们可以预见未来数字员工的开发门槛将大大降低。
首先,大语言模型可以让任何人都通过自然语言来“培养”数字员工。我们可以将数字员工的“培养”过程类比于雇佣一位新员工,我们可以与他进行对话,提供一些相关的资料让他学习,并通过实践来加强学习效果。未来,数字员工的“培养”过程也应该如此,我们只需要通过自然语言来教它们。如果它们的表现不佳,我们可以通过自然语言来“调教”它们。这才是真正的零代码开发。
其次,我们可以进一步拓展思路。大语言模型的输入和输出都是序列,被称为“token”。在大语言模型中,这些“token”通常指字符,但实际上它们可以是任何符号或内容。如果我们将电脑上所有操作行为也定义成“token”,那么大语言模型就可以观察我们的操作行为(模型输入),并预测接下来要执行的操作(模型输出)。换句话说,模型可以通过学习用户的行为来主动推荐数字员工。例如,假设我们需要将一张表格中的许多客户信息录入到CRM系统中。如果CRM系统没有提供批量导入功能,我们就需要逐条录入客户信息。当我们录入前几条客户信息后,大语言模型可以通过观察我们的操作,预测我们可能想要将所有客户信息录入到CRM系统中。这时候,数字员工就会出现并询问我们是否需要这么做,然后自动完成剩下的工作。
对话将成为数字员工的入口
大语言模型提供了一种自然的人机交互方式,这对数字劳动力有两方面的影响。
未来每个软件都将具备对话能力,甚至有些软件不再需要图形化的界面,而是只有对话式的界面。这将大大降低软件的学习和使用门槛,同时也意味着未来机器与机器之间也有可能会以自然语言的方式进行交互。
目前,大多数情况下我们还需要通过图形化交互界面来使用数字员工,这有一定的学习门槛,使用也不够便利,这在一定程度上阻碍了数字员工的普及。未来,对话将成为数字员工的入口,任何人都可以通过自然语言交互的方式向数字员工传递指令,让数字员工执行相关任务。这将使数字员工大规模普及,每个人都将拥有数字员工。
大语言模型应用于数字员工的挑战
大语言模型虽然强大,但其在数字化劳动力中的大规模应用,仍然面对以下几个挑战。
首先,当前的大语言模型缺少领域知识,只能作为一个通用的助手,而不能成为一个领域的专家。各行各业里,每个企业和组织内部,都有大量的领域知识,只有将这些领域知识融入到大语言模型中,模型才能发挥充分的价值。因此,高效的模型微调是大语言模型在垂直领域落地的关键。
其次,当前的大语言模型输出以自然语言为主,无法真正执行任务。即便大语言模型可以输出代码,它和企业的业务系统、业务流程依然是割裂的。因此,将大语言模型与UI自动化、API自动化等软件集成是一种解决方案,让大语言模型不仅能说,也能做。
最后,当前的大语言模型不能提供个性化服务,因为训练成本非常高,无法为每个用户训练不同的模型。然而,随着技术的快速发展,模型的最大输入长度将持续增加,从而可以将个性化信息放在上下文中作为模型的输入,实现个性化服务。
1.本内容作为作者独立观点,不代表RPA学习天地立场,RPA学习天地仅提供信息存储空间服务。
2.如果对本稿件有异议或投诉,请联系客服微信号。
 如需购买,请微信扫描二维码
如需购买,请微信扫描二维码  支付宝扫一扫
支付宝扫一扫 相关推荐
-
凯诺利用 AI 增强型自动化改变工作方式,重拾工作价值
凯莱英临床(凯诺)是凯莱英医药集团(股票代码:002821.SZ/6821.HK,以下简称“凯莱英”)旗下全资子公司。业务范围涵盖从新药 IND 到 NDA 的一站式全流程,形成了…
-
以赛促用,激发创新,大型生物科技集团用RPA大赛引领数字变革 | 优宁维
“以赛促教、以赛促学、以赛促用”不仅是大型集团在推动RPA竞赛过程中的手段,更是最终目标。 影刀在协助云南白药、南网储能、顾家家居、中通服等企业落地RPA大赛的过程中发现,RPA大…
-
弘玑Cyclone RPA为无锡农商行提供数字化路径,每月节省300小时人力成本
对金融业而言,推动数字化转型既是大势所趋,也是机遇所在,升级转型将创造新价值。伴随业务体量的增加,无锡农村商业银行(下称“无锡农商行”)在业务处理效率、业务能力拓展等方面对“科技赋…
-
弘玑 AI 智能体携手联想共赴人工智能新征程
在人工智能蓬勃发展的时代浪潮中,弘玑始终秉持创新精神,聚焦 AI 智能体领域的深耕细作。近期,弘玑在 AI 智能体方面取得了重大突破,凭借卓越的技术实力和不懈的研发投入,收获了令人…
-
向您的金融服务(智能体)新同事问好
想象这样一个金融服务场景:贷款审批秒级完成,理赔处理精准无误,合规管理轻松无忧。这并非遥不可及,而是智能体自动化(Agentic Automation)带来的未来。智能体自动化通过…
-
源程鑫:将RPA上升到企业战略层,让RPA发挥最大价值
互联网经济为消费增长带来了巨大的突破,在大众消费观变化、下沉市场增长、电商直播兴起、疫情长期化常态化等多类原因的助推下,2021年的电商市场格外精彩。 同时,随着线上线下场景融合、…
-
UiPath 助力上海纳铁福实现数字化转型
上海纳铁福传动系统有限公司(以下简称“纳铁福”)主要生产汽车传动系统总成产品及零件,立足于“秉承精益,追求卓越,成为国际一流的传动系统供应商”的企业愿景,竭诚为国内外主机厂提供配套…
-
企业专用知识库+DeepSeek:为什么企业需要一套企业级知识库系统
从DeepSeek到知识库:为什么企业需要一套企业级知识库系统 01 DeepSeek需借助企业知识库以解答专业性和独特性问题 在商业环境迅速变化的过程中,企业所面临的挑战正变得越…
-
签约喜讯丨格力牵手实在智能,数字员工赋能客户高质效服务
近日,电器行业“领跑者”珠海格力电器股份有限公司(以下简称 “格力”,股票代码:000651.SZ)与实在智能达成合作。格力引入实在智能处于行业领先地位的 AI+RPA 技术,全力…
-
国网合肥供电公司:数字助手助力提效减负加速数字化转型
国网合肥供电公司成立于1962年,是国网安徽省电力公司直属的国有大型电网经营企业。公司承担着合肥市752万人口、311万电力客户的供电任务,营业区总面积1.14万平方公里。 近年来…
